On February 26, 2026, we officially launched Unisound U1-OCR, the first industrial-grade document intelligence foundational large model. With five core advantages—state-of-the-art performance, verifiable reliability, plug-and-play functionality, efficient deployment, and strong adaptability—it redefines traditional document processing boundaries, ushering in the OCR 3.0 era and laying a solid foundation for subsequent iterations of the U1-OCR series models.
Today, after undergoing fundamental architecture restructuring and extensive real-world scenario testing, Unisound’s U1-OCR capabilities have achieved further evolution with the launch of a series of models. Simultaneously, the model has been fully integrated into Unisound Token Hub’s large-scale model service platform, offering standardized APIs for one-click integration and on-demand invocation. Adopting a Token-based billing model, this solution significantly reduces enterprise adoption costs and deployment barriers, enabling document intelligence capabilities in the OCR 3.0 era to benefit broader industries.
Key Highlights
Full API officially launched: the Unisound Token Hub large model service platform now available, with standardized interfaces for one-click invocation and Token-based billing—ready to use out of the box.
Authoritative technical certification: Core paper included in ACL 2026, top-ranked in dual authoritative datasets, with verifiable and traceable performance
Architectural Paradigm Upgrade: Abandoning traditional NMS, adopting a unified structure to refine solutions for cascading errors and achieve a qualitative leap in complex layout parsing.
Industry-wide scenario adaptation: Complex documents in finance, healthcare, education, transportation, and more – structural understanding and sequential recovery in one step
API entry:
- https://maas.unisound.com/
Paper View:
- https://arxiv.org/pdf/2601.07483
- https://arxiv.org/pdf/2604.02692

Unisound U1-OCR Document Analysis Capability Demonstration Video
1. Addressing Industry Pain Points: Why Does Downstream Operations Remain Chaotic Despite Adequate OCR Accuracy?
In real-world business scenarios, the core requirements of document parsing extend far beyond mere text recognition. Whether dealing with common documents such as academic papers, research reports, textbooks, or exam papers, or complex PDFs, our system must not only identify text but also comprehend the structural organization of pages and accurately reconstruct content sequences that align with human reading habits. Only by addressing two fundamental questions — “What constitutes each section?” and “What order should these sections be interpreted?” — can document content reliably support critical downstream tasks such as information extraction, retrieval, question-answering, and knowledge repository management.
This indicates that the key to document parsing capabilities has long transcended OCR recognition accuracy itself, with the core focus lying in whether the system can truly comprehend page structure and content hierarchy. Real-world business documents rarely consist of linear plain text, as they typically integrate multiple elements including headings, body text, charts, tables, headers/footers, footnotes, and multi-column layouts. Systems limited to text recognition without accurate layout analysis and regional correlation assessment are prone to issues such as disordered text-image sequencing, title-body confusion, sequential misalignment of multi-column content, and contextual misplacement. These problems ultimately compromise the stability of critical tasks including field extraction, knowledge database integration, and question-answer retrieval systems.
II. Concretizing Typical Pain Points: The Analysis Dilemma in Complex Pages
In complex, densely structured document pages, layout detectors often generate multiple overlapping candidate boxes with slightly different boundaries for the same content block. While the system may appear to “detect all content” on the surface, not all candidate boxes can be directly utilized for downstream parsing. The critical factor lies not in the quantity of candidate boxes, but rather in the accuracy, completeness, and proper sequencing of the ultimately retained regions.
If these candidate boxes are not processed and are directly fed into the downstream parser, it can lead to content duplication, structural disorder, and even disruption of the normal reading sequence. Traditional industry solutions typically employ Non-Maximum Suppression (NMS) to remove duplicates among candidate boxes—eliminating redundant results from overlapping regions while retaining only one candidate box. However, on complex real-world pages, heuristic NMS alone often proves unstable: although multiple candidate boxes may point to the same content, their integrity and positioning accuracy vary. NMS can only perform duplicate removal but may fail to retain the region most suitable for downstream parsing, potentially mistakenly eliminating areas with more precise positioning and broader coverage.
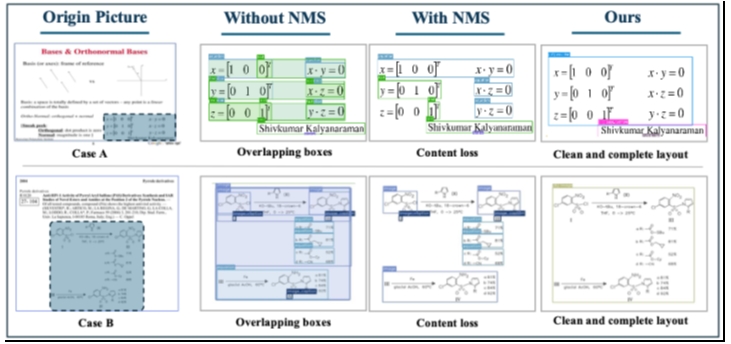
In practical application scenarios, this pain point becomes particularly pronounced:
In agricultural newspaper layouts, multi-column articles often exhibit disordered column skipping during systematic reading. The intended top-to-bottom and left-to-right reading sequence frequently results in mid-left-to-right transitions followed by abrupt returns to the left column, completely deviating from normal newspaper reading patterns and causing logical fragmentation in comprehension.

Consider, for instance, high-density pages featuring Sudoku puzzles, word puzzles, and crossword grids. Such pages contain numerous complex elements and intertwined functional areas, demanding greater proficiency in understanding the model’s layout architecture.
In such entertainment formats, text, game grids, and question descriptions are densely packed together, making it difficult for the system to distinguish which statements correspond to which games. This often leads to incorrect pairing of text with grids and arbitrary navigation between different games, resulting in both incoherent reading sequences and misidentification of content attribution.
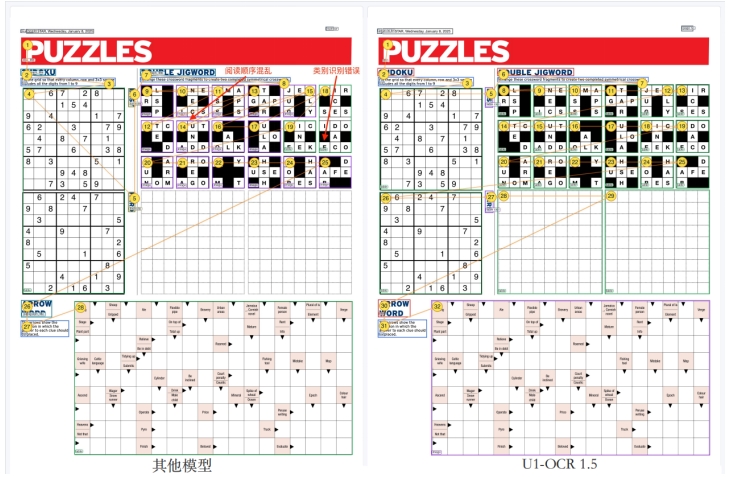
This epitomizes the core challenge in complex document parsing: the issue lies not in text recognition failure, but in the instability of structural information organization, which impedes efficient delivery to downstream modules.
III. Breakthrough Strategy: From “Stacking Independent Modules” to “Refining the Unified Structural Assumption Pool”
Addressing these industry pain points, we believe the key breakthrough in complex document parsing lies not only in improving OCR recognition accuracy or single-point detection metrics, but more crucially in ensuring a seamless structural transition from detector to parser.
Traditional approaches typically treat candidate region filtering, region retention, and reading sequence restoration as three separate steps: Non-Maximum Suppression (NMS) handles deduplication, while the sorting module manages sequence alignment. Although this modular approach works effectively for simple pages, it is prone to cascade errors in complex pages. The sorting process relies on an unstable candidate set, and any subsequent filtering changes to retained regions may invalidate the original sequence alignment.
To address this prevalent industry challenge, U1-OCR employs a parsing architecture tailored for complex document scenarios: instead of treating detector outputs directly as layout inputs for the parser, it treats them as a “pool of structural hypotheses awaiting refinement.” A lightweight structural refinement module is integrated before the parser takes over, enabling unified modeling of candidate region retention, positioning, and sequencing. Ultimately, positioning corrections, instance retention, and reading order restoration are generated synchronously from a single refined state, ensuring the downstream parser receives a clean, well-structured layout set rather than merely the raw heuristic post-processing results.
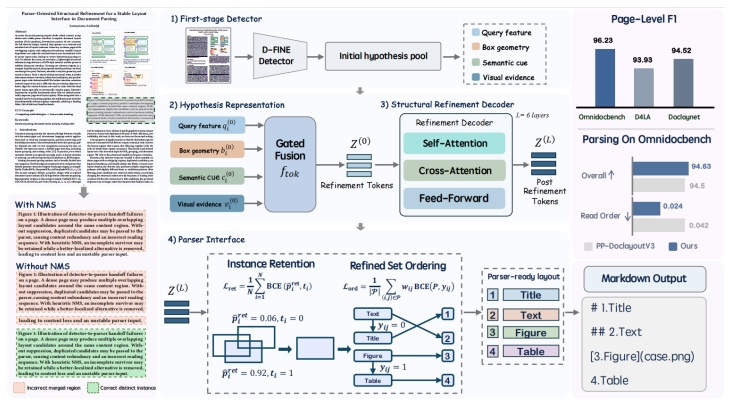
Fundamentally, our design can be decomposed into two core subtasks: first, structural recognition, which involves identifying the content type of each region on the page and determining which regions should be retained; second, sequential reasoning, which entails planning a logical reading path for the retained regions.
IV. Core Technology Analysis: Four Key Design Elements to Strengthen Technological Barriers
The core logic of U1-OCR document parsing operates as follows: After receiving an image of the document page, the model first generates an initial candidate hypothesis pool through a first-stage detector, followed by unified structural refinement prior to parser integration. Unlike traditional methods that rely on NMS (Non-Maximum Suppression) to determine candidate region retention, we treat detector outputs as a refined candidate set to construct a more stable layout for the parser. Its key technical advantages are reflected in four critical design aspects:
4.1 Structural Refinement for the Parser Interface
The core of U1-OCR lies not in optimizing individual local steps of detection or sorting, but in re-modeling the transition process from detector to parser. By introducing a lightweight fine-tuning phase before the parser interface, it enables localization correction, instance retention, and reading order restoration to be completed within a unified representation space, significantly enhancing the stability of the final structural interface.
4.2 Bidirectional Spatial Position Guidance of Attention
During the structural refinement phase, a bidirectional spatial position-guided attention mechanism is employed to jointly model relationships between candidate regions and image evidence. This design enables current candidate region updates to not only rely on local visual information but also integrate spatial distribution patterns of other candidate regions and global layout arrangements. It effectively addresses structural ambiguities in multi-column layouts, competing adjacent text blocks, and mixed text-image arrangements, thereby establishing a robust foundation for subsequent instance preservation and sequential restoration processes.
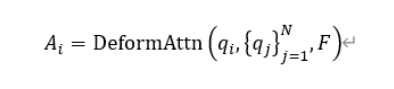
4.3 Retention-Oriented Supervision
By introducing retention-oriented supervision objectives, the model learns to capture the structural competitive relationships between candidate regions rather than relying on fixed IoU suppression rules to determine region retention, thereby reducing content loss and structural degradation caused by mechanical filtering in complex pages.
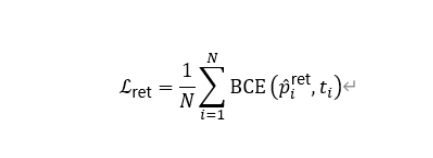
4.4 Difficulty Perception Sequential Constraints
In reading sequence recovery, the model captures the sequential relationships of retained instances and introduces difficulty-aware weighting to enhance sorting learning between complex regions. This enables the model to recover more consistent global reading paths based on shared fine-tuned structural states, particularly suitable for complex layouts such as hurdles, nesting, and mixed text-image arrangements.
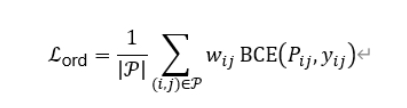
V. Experimental Validation: Dual Datasets Achieve Peak Performance with Comprehensive Leadership
To validate the effectiveness of our product’s technical solution, we conducted evaluations from two dimensions: First, we employed the pageIoU protocol to independently assess the page-level structural quality of the final retained layout set. Second, by fixing the PaddleOCR-VL-1.5 backend and replacing only the frontend layout analysis module, we observed whether a more stable detector-parser interface could enhance end-to-end parsing performance—focusing primarily on improvements in reading sequence-related metrics. This evaluation covered two authoritative datasets: OmniDocBench and D4LA.
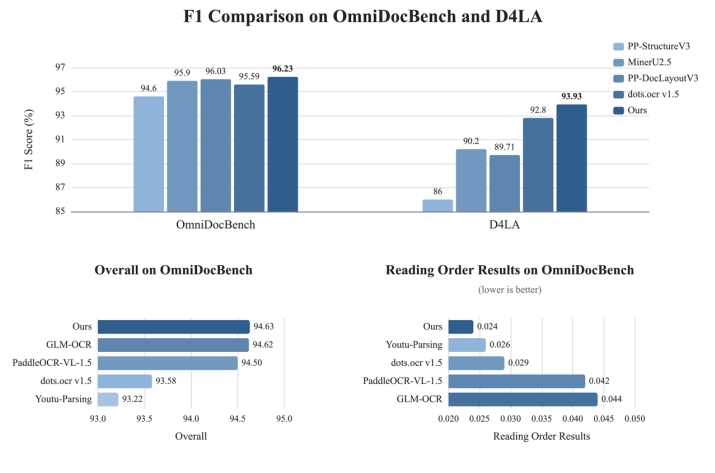
5.1 Main Result Comparison: Leading performance in structural comprehension across datasets
Experimental results demonstrate that U1-OCR achieves the highest F1 score across both datasets, showcasing robust layout structure comprehension and cross-dataset generalization capabilities.
On the OmniDocBench dataset, our product achieved an F1 score of 96.23, outperforming PP-DocLayoutV3 (96.03), MinerU2.5 (95.90), dots.ocr v1.5 (95.59), and PP-StructureV3 (94.60). On the D4LA dataset, we topped the rankings with an F1 score of 93.93, surpassing dots.ocr v1.5 (92.80), MinerU2.5 (90.20), PP-DocLayoutV3 (89.71), and PP-StructureV3 (86.00).
These results demonstrate that U1-OCR achieves superior performance in complex structural layouts and diverse page layouts, particularly excelling in region boundary detection, category classification, and structural reconstruction. It precisely achieves the design objective of “stabilizing competing candidate hypotheses into parser-ready structural inputs.” (Note: PP-DocLayoutV3 is the layout analysis module utilized by PaddleOCR-VL-1.5 and GLM-OCR.)
5.2 Comparison of OCR parsing results: Optimal accuracy in reading sequence recovery
On the OmniDocBench dataset, U1-OCR demonstrates outstanding comprehensive parsing capabilities and reading sequence recovery performance simultaneously:
Overall, our product scores 94.63, slightly higher than GLM-OCR (94.62) and outperforming PaddleOCR-VL-1.5 (94.50), dots.ocr v1.5 (93.58), and Youtu-Parsing (93.22), demonstrating robust competitiveness in end-to-end document parsing. In the core reading order metric Read Order Edit, we achieved the optimal score of 0.024 (the lower the better), significantly surpassing Youtu-Parsing (0.026), dots.ocr v1.5 (0.029), PaddleOCR-VL-1.5 (0.042), and GLM-OCR (0.044).
The experiments further demonstrated that heuristic NMS only alleviates the repeated box problem but fails to achieve consistency among localization, retention, and sorting. In contrast, our unified fine-tuning approach achieves structural balance among these three aspects across multiple datasets, showing significantly superior performance in reading order restoration compared to the traditional “detect first, then apply independent sorting model” method, thereby validating the effectiveness of our technology.
From OCR Recognition to Document Understanding: Empowering Industry Digital Transformation
The goal of U1-OCR extends far beyond merely “recognizing text”; it aims to effectively address the challenges of structural comprehension and reading sequence restoration in complex document pages. We break down document parsing into two core tasks: “structural recognition” and “sequence reconstruction,” and have developed specialized key technologies centered around these objectives. These efforts have not only yielded leading results across multiple publicly available and authoritative datasets but also provided a more stable and reliable approach for the detector-to parser handoff—a critical yet often overlooked phase in real-world business scenarios. The findings of the relevant paper corroborate this: optimizing the parser interface represents a practical and effective pathway to enhance the document parsing capabilities of explicit DLA pipelines.
This signifies that document parsing has evolved from basic OCR text recognition to advanced document comprehension capabilities tailored for real-world business needs. With the full deployment of U1-OCR on Unisound’s Token Hub large model service platform, standardized APIs and one-click invocation functions have been simultaneously launched. These innovations will significantly lower the technical barriers to document intelligence applications, delivering efficient and precise document analysis services across industries including healthcare, transportation, finance, and education. The solution is designed to facilitate seamless digital transformation and upgrading across sectors.
Media Contact
Company Name: Unisound AI Technology Co., Ltd.
Contact Person: Zhou Ziding
Email: Send Email
Country: China
Website: https://www.unisound.com/


